The era of experimental AI has reached its expiration date. We have moved beyond the novelty of generative chat into the high-stakes theater of Agentic AI – autonomous systems architected to execute multi-step workflows, orchestrate APIs, and commit to real-time decisions on behalf of the enterprise.
As an engineering leader, you recognize that this shift is fundamental. Traditional quality assurance—built on the deterministic foundation of “if X, then Y” – is obsolete in a world governed by probability. When an agent hallucinates a transaction or triggers a biased recommendation, it isn’t just a “bug”; it is a catastrophic breach of user trust and a significant legal liability.
Building trust in 2026 is no longer about hoping the model behaves; it is about hardening your stack with a verifiable framework of accountability.
Core Pillars for Testing Agentic AI
Non-Deterministic Testing
- The Definition: AI is probabilistic, meaning identical prompts can yield varied outputs. Testing Agentic AI requires moving from “Exact Match” assertions to Semantic Consistency.
- The Goal: Calibrate the system to remain within a “logical safety zone” despite linguistic variations.
- Analogy: Testing a barista—the latte isn’t identical to the milligram every time, but it must never be a cup of tea.
LLM-as-a-Judge
- The Definition: Deploying a high-reasoning “senior” model (e.g., Claude 3.7) to audit and grade the outputs of a specialized “junior” task model.
- The Goal: Streamline complex quality reviews at a scale that manual human intervention cannot sustain.
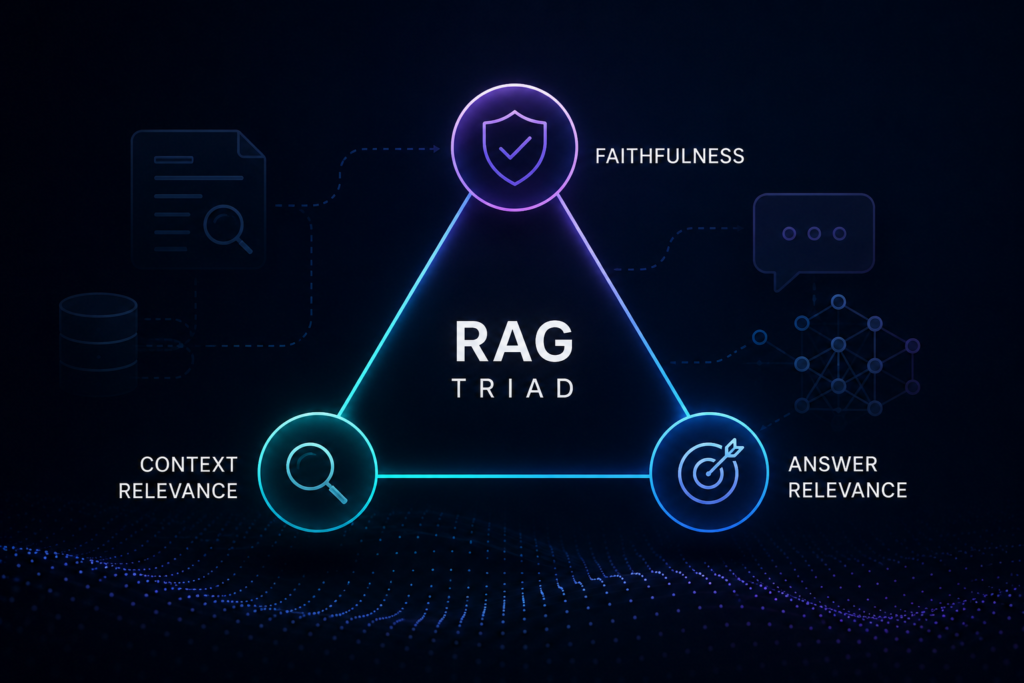
The RAG Triad
- The Definition: A diagnostic frame for Retrieval-Augmented Generation (RAG) designed to isolate failures:
- Context Relevance: Did the retriever pull the precise data required?
- Faithfulness: Is the response grounded exclusively in that data? (The definitive AI Hallucination testing checkpoint).
- Answer Relevance: Did the agent resolve the specific user intent?
We covered this in more detail in our deep dive at The RAG Triad in Practice: Faithfulness, Context Relevance & Answer Relevance with RAGAS
Agentic Red Teaming
- The Definition: Proactively attacking your own AI to uncover vulnerabilities like Indirect Prompt Injection.
- The Goal: Hardening the system’s security perimeter before an adversarial actor can exploit it.
Bounded Autonomy
- The Definition: Validating an agent’s ability to recognize its own constraints and trigger a human hand-off.
- The Goal: Neutralize “hallucinated actions”—such as an agent confidently purging a production database it was never authorized to touch.
FAQ: High-Performance AI Quality & Evaluation Frameworks
Q1: What are the evaluation frameworks for 2026?
- DeepEval: The premier choice for Testing AI applications via unit tests within Python CI/CD workflows.
- Ragas: The gold standard for a reference-free RAG evaluation framework.
- Arize Phoenix: Specialized for open-source observability with advanced embedding visualization.
- LangSmith: Essential for teams deep in the LangChain ecosystem for orchestrated tracing and debugging.
Q2: How do you execute AI Hallucination testing effectively?
We implement Faithfulness and Groundedness scores. These metrics mathematically verify what percentage of “atomic facts” in an AI’s response are supported by your source context. When an agent adds an unverified fact, the hallucination rate is immediately flagged for intervention.
Q3: How do you mitigate bias and other Agentic AI risks?
Testing for bias involves Demographic Parity audits. We strategically modify “protected attributes” (e.g., gender or location) in prompts to verify that the agent’s logic remains unbiased and fair. We also utilize Bias Scores to identify imbalances in the underlying training data.
Q4: What is the primary difference between testing GenAI and Agentic AI?
GenAI testing validates the words; Testing Agentic AI validates the actions (API calls, tool utilization, and sequential logic) to ensure they are safe, authorized, and logical.
Q5: What is “Context Poisoning” in modern security?
Testing AI applications requires a “security-first” mindset. Context poisoning occurs when an attacker injects a “Trojan” document into your RAG knowledge base to hijack the agent’s logic from the inside out.
Q6: How do you evaluate a “Multi-Agent” swarm?
By stress-testing the A2A (Agent-to-Agent) communication protocols. This ensures a “Planner” agent isn’t broadcasting corrupted or unauthorized instructions to “Executor” agents.
Q7: How does “Explainability” (XAI) impact trust?
We engineer a reasoning log—an “audit trail”—for every decision. This allows us to verify the why behind every autonomous action, ensuring complete transparency.
Q8: How do you sustain AI reliability in production?
By monitoring for Model Drift. We continuously benchmark live outputs against a human-verified Golden Dataset (ground truth) to detect and remediate quality drops in real-time.
Q9: Why is a “Judge” model critical for evaluation?
To eliminate self-bias. A model is often blind to its own hallucinations; using a different model family ensures a rigorous, independent audit of the output.
Q10: Is “Human-in-the-loop” still a requirement?
Absolutely. In 2026, the human engineer has evolved into the Quality Architect. While AI executes the testing, the human defines the Golden Datasets and maintains final authority over high-risk escalation points.
Building verifiable trust isn’t an accident—it is a rigorous engineering discipline. By moving beyond the demo and hardening your releases, you ensure your AI remains an asset, not a liability.